Содержание
[История] Операция «Искра» — Новости
ВНИМАНИЕ! Устаревший формат новостей. Возможны проблемы с корректным отображением контента.
12 января 1943 года в ходе операции «Искра» начался прорыв блокады Ленинграда. Благоприятная обстановка на советско-германском фронте, связанная, прежде всего, с масштабной операцией по разгрому окруженной группировки 6 армии Паулюса под Сталинградом, позволяла рассчитывать на успешное проведение наступления с целью прорыва кольца окружения вокруг города. Из-за сложной ситуации германские войска не могли оперативно перебросить подкрепления на другой участок фронта.
Тем не менее, оборона Шлиссельбургско-Синявинского выступа, называемого немцами «бутылочным горлом», организовывалась в течении долгих 16 месяце осады Ленинграда и представляла собой непреодолимую стену многочисленных узлов обороны с хорошо пристрелянными позициями. Советским войскам предстояло ликвидировать этот оборонительный рубеж и соединить окруженный, измотанный голодом и холодом город с «большой землей».
|
Положение под Ленинградом к концу 1942 г.
|
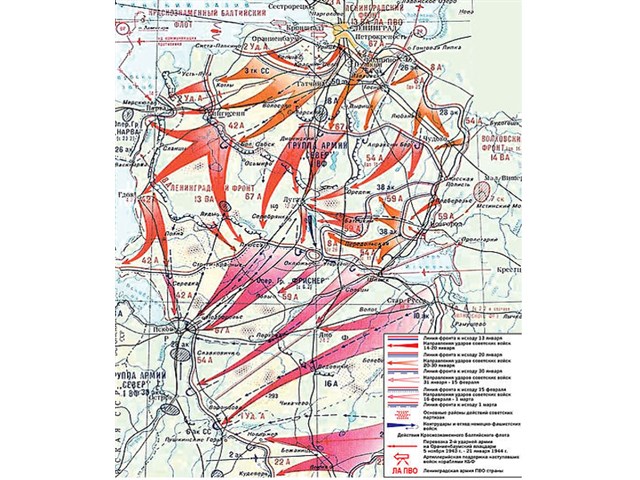
Операция «Искра» была проработана еще в ноябре 1942 года, и после согласования со Ставкой Верховного Главнокомандующего командование обороны Ленинграда приступило к мероприятиям по ее реализации. 8 декабря 1942 года И.В. Сталин и Г.К. Жуков, как заместитель Верховного, подписали директиву, в которой в частности говорилось: «Совместными усилиями Волховского и Ленинградского фронтов разгромить группировку противника в районе Липки, Вайтолово, Московская Дубровка, Шлиссельбург – таким образом разбить осаду города Ленинграда». Место прорыва было определено южнее ладожского озера, где Волховский и Ленинградский фронты находились друг от друга на расстоянии 12-14 км.
Со стороны Ленинградского фронта наступление вела 67 армия под командованием М. П. Духанова. Волховский фронт вводил в прорыв 2-ю ударную армию под командованием Романовского. Ночью 12 января 1943 года по немецкой обороне был нанесен авиационный удар, который в 9:30 утра сменился «огненным валом» артиллерийской подготовки: в линии прорыва огонь открыли 1697 орудий и минометов. Огонь вела артиллерия обоих фронтов. Помимо этого, огнем 77 тяжелых орудий наносил мощные удары по немецким войскам и Балтийский флот. Завершали «огненный вал» гвардейские реактивные минометы.
П. Духанова. Волховский фронт вводил в прорыв 2-ю ударную армию под командованием Романовского. Ночью 12 января 1943 года по немецкой обороне был нанесен авиационный удар, который в 9:30 утра сменился «огненным валом» артиллерийской подготовки: в линии прорыва огонь открыли 1697 орудий и минометов. Огонь вела артиллерия обоих фронтов. Помимо этого, огнем 77 тяжелых орудий наносил мощные удары по немецким войскам и Балтийский флот. Завершали «огненный вал» гвардейские реактивные минометы.
В 11:40 дивизии первого эшелона 67-й армии – 45-я гвардейская, 268-я, 136-я и 86-я – перешли в наступление. Несмотря на то, что передний край немцев молчал после нанесенного артудара, советским подразделениям предстояло форсировать 800-метровую ленту Невы. Возникли трудности с переправой на другой берег танков Т-34 и КВ. До сегодняшнего дня отдельные машины извлекают из толщи невской воды. Саперы сумели соорудить три ветки переправ, похожие на железнодорожную колею из льда и дерева.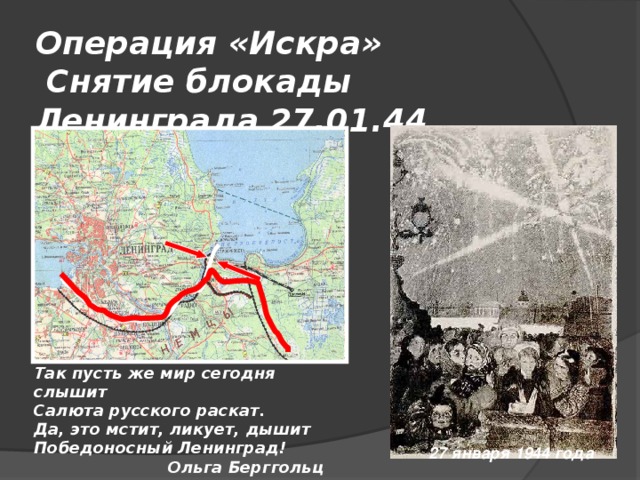 Две из них вышли из строя, и лишь по третьей в ночь на 14 января советские солдаты сумели переправить 90 танков.
Две из них вышли из строя, и лишь по третьей в ночь на 14 января советские солдаты сумели переправить 90 танков.
На правом фланге прорыва 67-й армии, в полосе наступления 45-й гвардейской дивизии нашим войскам пришлось вести сдерживающие бои: слишком сильна оказалась в этом месте немецкая оборона. С другой стороны, это позволило подразделениям 136-й, 268-й и 123-й дивизии 2-го эшелона успешно продвигаться в направлении Волховского фронта. наступавшая же на левом фланге на Шлиссельбург 86-я дивизия не сумела пересечь Неву и понесла тяжелые потери. Отправленные в прорыв на данном направлении 13 стрелковая дивизия и 142 стрелковая бригада с задачей также не справились.
Особо упорные бои в ходе наступления шли за немецкие опорные пункты в рабочих поселках №1 и №5 16 января 1943 года. Эти поселки постоянно переходили из рук в руки. Основным местом прорыва оказался участок фронта между 2-м городком и Шлиссельбургом. Бои на этом направлении вели 136 стрелковая дивизия и 61-я бригада легких танков. В недописанном письме обер-ефрейтора Вормбекера можно прочитать следующее: «Я не могу дольше переносить этот кошмар. Уже неделю бушует над нами ураган огня и стали. Мы совсем теряем голову. Из крепости они бьют прямой наводкой как из винтовки. Они, а не мы – хозяева положения. Какое страшное слово – Ладога!!!».
Бои на этом направлении вели 136 стрелковая дивизия и 61-я бригада легких танков. В недописанном письме обер-ефрейтора Вормбекера можно прочитать следующее: «Я не могу дольше переносить этот кошмар. Уже неделю бушует над нами ураган огня и стали. Мы совсем теряем голову. Из крепости они бьют прямой наводкой как из винтовки. Они, а не мы – хозяева положения. Какое страшное слово – Ладога!!!».
|
«Здесь лежат ленинградцы…»
Пискарёвское мемориальное кладбище (Санкт-Петербург).
|
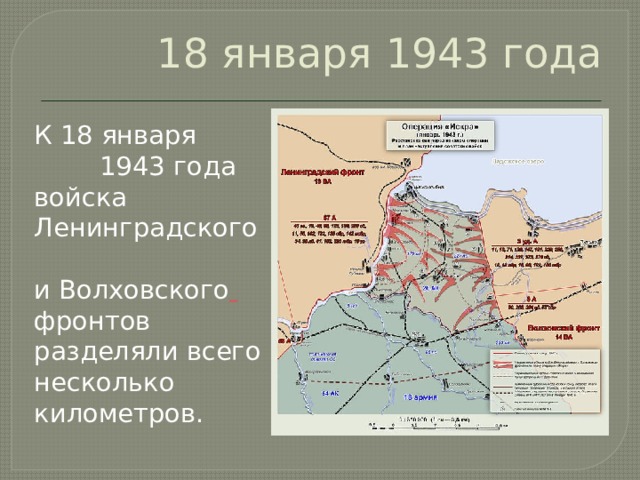
Лишь 18 января 1943 года рабочий поселок №5 был наконец освобожден советскими войсками. В середине того же дня части 86-й стрелковой дивизии освободили Шлиссельбург и закрепили на колокольне красный флаг. Вечером подразделения Ленинградского и Волховского фронтов завершили прорыв и соединились. Несмотря на то, что удалось расчистить лишь 8-11 км коридор, позволивший в скором времени построить железнодорожную линию Поляны – Шлиссельбург, эта победа оказалась поистине бесценной для советских людей. В город вернулась нормальная (по военным меркам) жизнь. Продовольственные нормы в скором времени достигли уровня других советских городов.
Несмотря на то, что удалось расчистить лишь 8-11 км коридор, позволивший в скором времени построить железнодорожную линию Поляны – Шлиссельбург, эта победа оказалась поистине бесценной для советских людей. В город вернулась нормальная (по военным меркам) жизнь. Продовольственные нормы в скором времени достигли уровня других советских городов.
Почти 33000 воинов заплатили за это своими жизнями. Вспомним же их знаменитыми строками ленинградской поэтессы Ольги Берггольц: «Никто не забыт, ничто не забыто».
Обсуждение на форуме
Читайте также:
МиГ-29 (9-13): точка опоры
- 9 декабря 2022
Thunder Show: Охотник на кабанов
- 9 декабря 2022
F-16A Fighting Falcon: американский ястреб
- 9 декабря 2022
Снова в продаже: Ми-24Д!
- 9 декабря 2022
Результаты для «ПО «Искра»» — Википедия — Study in China 2023
Результаты для «ПО «Искра»» — Википедия — Study in China 2023 — Wiki Русский Искра
Искра может означать: Искра — искровой разряд.
 Искра — мельчайшая частичка горящего или раскалённого вещества. Названия населённых пунктов: Искра — деревня…
Искра — мельчайшая частичка горящего или раскалённого вещества. Названия населённых пунктов: Искра — деревня…Операция «Искра»
Опера́ция «И́скра» (нем. Zweite Ladoga-Schlacht — Вторая битва у Ладожского озера) — наступательная операция советских войск во время Великой Отечественной…
Результаты для «ПО «Искра»» — Википедия — Study in China 2023 — Wiki Русский Искра жизни
«И́скра жи́зни» (нем. Der Funke Leben) — роман Эриха Марии Ремарка, вышедший в 1952 году. Посвящён сестре писателя Эльфриде Шольц. У писателя было две…
Бабич, Искра Леонидовна
И́скра Леони́довна Ба́бич (10 января 1932, Сочи — 5 августа 2001) — советский и российский кинорежиссёр и сценарист. Родилась 10 января 1932 года в Сочи…
Искра 226
Искра-125, Искра-1256). В журнале «Микропроцессорные средства и системы» говорилось о целенаправленной программе, в ходе которой была создана «Искра-226»:.
..Искра-1030
техники «Искра» (СКБ ВТ «Искра»), входящем в Ленинградское научно-производственное объединение (ЛНПО) «Электронмаш». Выпускался серийно на ПО «Искра» в Смоленске…
Искра (газета)
газеты стала фраза «Из искры возгорится пламя», взятая из стихотворения поэта-декабриста А. И. Одоевского. По задумке Ленина «Искра» должна была сплотить…
Пучков, Дмитрий Юрьевич (перенаправление с Божья искра)
Широкая известность пришла к Гоблину после основания им студии «Божья искра», в рамках которой были выпущены пародийные переводы трёх частей киноэпопеи…
Результаты для «ПО «Искра»» — Википедия — Study in China 2023 — Wiki Русский Ленинская Искра
Ленинская Искра — название населённых пунктов в России: Ленинская Искра — посёлок в Котельничском районе Кировской области.
Ленинская Искра — село в Медвенском…Результаты для «ПО «Искра»» — Википедия — Study in China 2023 — Wiki Русский Искры
области Республики Беларусь. Искра Улица Искры — название улиц в различных населённых пунктах государств бывшего СССР. «Искры из глаз» — пятнадцатый фильм…
Результаты для «ПО «Искра»» — Википедия — Study in China 2023 — Wiki Русский Искра (предприятие)
Искра (компания, Украина) — ведущий производитель электроламп Украины Искра (предприятие, Красноярск) — АО «Красноярское конструкторское бюро «Искра» (Группа…
Рубин (футбольный клуб) (перенаправление с Искра (футбольный клуб, Казань))
футбольный клуб из города Казани. Основан 20 апреля 1958 года под названием «Искра» как команда Казанского авиационного завода № 22 имени С. П. Горбунова….
НПО «Искра»
ПАО НПО «Искра» — одно из крупнейших машиностроительных предприятий России.
Проектировщик, производитель и поставщик оборудования для топливно-энергетического…Искра (журнал)
журнал «Искра». Тогда же было получено официальное разрешение, однако, ввиду нехватки денег, с выпуском пришлось повременить. Первый номер «Искры» вышел…
Искра (НПК)
«Научно-производственный комплекс „Искра“» Также, в 2003 году на вооружение украинской армии была принята разработанная КП НПК «Искра» радиолокационная станция…
Результаты для «ПО «Искра»» — Википедия — Study in China 2023 — Wiki Русский Искра (производственное объединение)
зарубежных производителей. ЭВМ «Искра 1030М» является продолжением серии ЭВМ Искра, выпускалась Производственным Объединением «ИСКРА» до 1992-1993 года; разработана…
Лоуренс, Искра
Искра Арабелла Лоуренс (от англ.
Iskra Arabella Lawrence) (род. 11 сентября 1990) — английская манекенщица и фотомодель. Также является главным редактором…Искры (дворянский род)
Искра (укр. Іскра) — малороссийский дворянский род казацкого старшинского происхождения. Родоначальник Яков Искра-Острянин— гетман Войска Запорожского…
Искра-1256
ленте (КНМЛ) и сам накопитель («Искра 005-33»). К процессорному блоку подключается клавиатура (устройство клавишное «Искра 007-30»).[источник не указан 1867…
Искра (футбольный клуб, Смоленск)
«Искра» — советский и российский футбольный клуб из Смоленска. Армейская команда «Искра» была образована в Смоленске в 1965 году; несколько предшествующих…
 Искра — мельчайшая частичка горящего или раскалённого вещества. Названия населённых пунктов: Искра — деревня…
Искра — мельчайшая частичка горящего или раскалённого вещества. Названия населённых пунктов: Искра — деревня…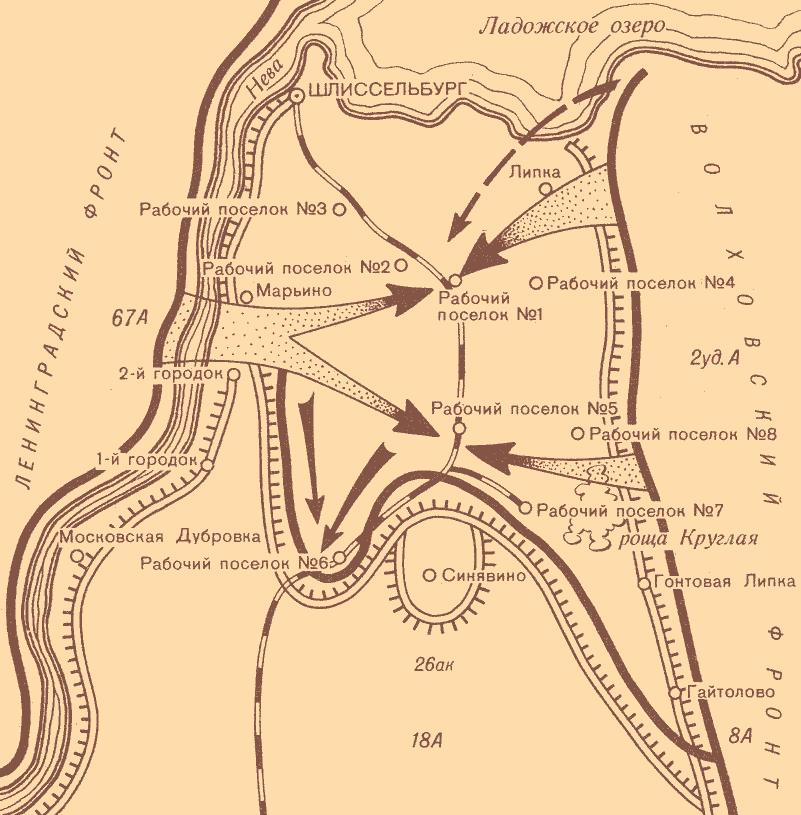 ..
.. Ленинская Искра — село в Медвенском…
Ленинская Искра — село в Медвенском… Проектировщик, производитель и поставщик оборудования для топливно-энергетического…
Проектировщик, производитель и поставщик оборудования для топливно-энергетического… Iskra Arabella Lawrence) (род. 11 сентября 1990) — английская манекенщица и фотомодель. Также является главным редактором…
Iskra Arabella Lawrence) (род. 11 сентября 1990) — английская манекенщица и фотомодель. Также является главным редактором…#Wikipedia® is a registered trademark of the Wikimedia Foundation, Inc. Wiki (Study in China) is an independent company and has no affiliation with Wikimedia Foundation.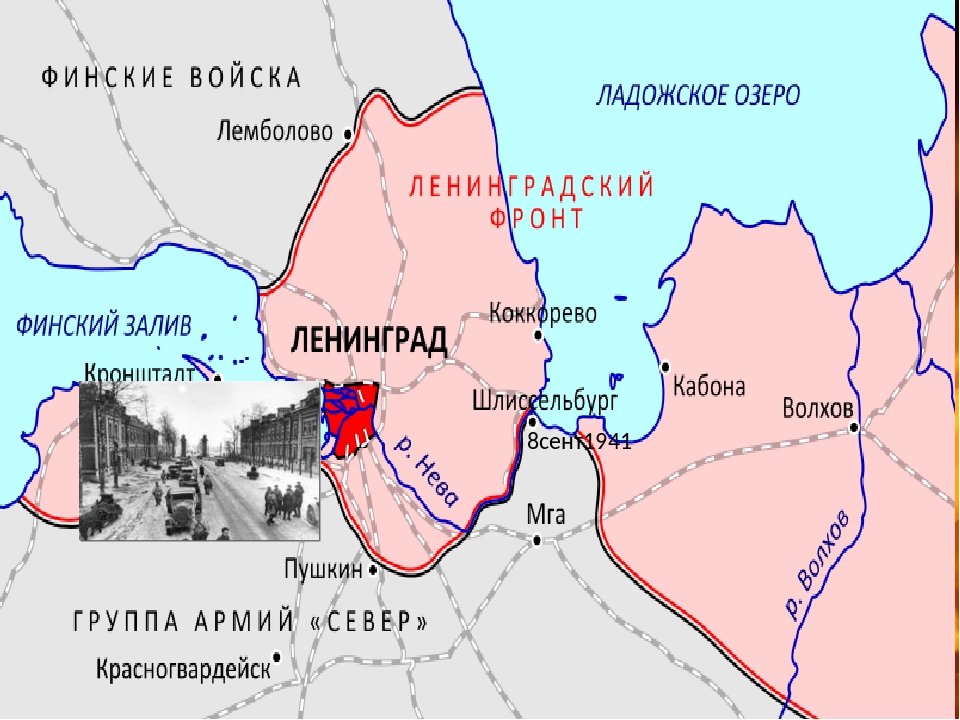
This article uses material from the Wikipedia article , which is released under the Creative Commons Attribution-ShareAlike 3.0 license («CC BY-SA 3.0»); additional terms may apply. (view authors). Images, videos and audio are available under their respective licenses.
🌐 Wiki languages: 1,000,000+ articlesEnglishРусскийDeutschItalianoPortuguês日本語Français中文العربيةEspañol한국어NederlandsSvenskaPolskiУкраїнськаمصرى粵語DanskفارسیTiếng ViệtWinaraySinugboanong Binisaya
🔥 Top trends keywords Русский Wiki:
Заглавная страницаМароккоБут, Виктор АнатольевичЧемпионат мира по футболу 2022Служебная:ПоискУэнздейЧемпионат мира по футболуКриштиану РоналдуСталин, Василий ИосифовичСборная Марокко по футболуРоссияОртега, ДженнаМесси, ЛионельЧемпионат мира по футболу 2018Список финалов чемпионатов мира по футболуYouTubeМбаппе, КилианГрайнер, БриттниАнтонов, Юрий МихайловичСборная Франции по футболуВКонтактеСборная Португалии по футболуНеймарКатарВторжение России на Украину (2022)Сборная Англии по футболуЖиру, ОливьеПелеМоскваСоединённые Штаты АмерикиЧемпионат мира по футболу 2026Чемпионат Европы по футболу 2020Сборная Аргентины по футболуСемейка Аддамс (персонажи)Семейка Аддамс (фильм)Яшин, Илья ВалерьевичКейн, ГарриГризманн, АнтуанСанкт-ПетербургСписок умерших в 2022 годуГруппа ВагнераПонаровская, Ирина ВитальевнаЧемпионат мира по футболу 2014Сборная Хорватии по футболуСталин, Иосиф ВиссарионовичРусский языкПутин, Владимир ВладимировичСборная Бразилии по футболуСписок игроков НХЛ, забросивших 500 и более шайбТу-141РоналдоУэнздей АддамсRobloxХорватияБег (фильм, 1970)Серов, Александр Николаевич (певец)ПортугалияПепе (футболист, 1983)Модрич, ЛукаБуну, ЯссинРиччи, КристинаАргентинаИвлеева, НастяЗидан, ЗинединОднопользовательская играРеграги, ВалидСоциальная сетьУкраинаБекхэм, ДэвидСенчина, Людмила ПетровнаНаселение МароккоСердце Пармы (фильм)Фрейндлих, Алиса БруновнаЛьорис, УгоОружейный баронВан Гал, ЛуиМногопользовательская играРымбаева, Роза КуанышевнаЛивакович, Доминик🡆 More
Process Wikipedia с использованием Apache Spark для создания горячих наборов данных | by Abhishek Mungoli
Создайте набор данных по вашему выбору из Википедии: Набор данных о знаменитостях
Википедия, Бесплатная энциклопедия
Должно быть, с большинством из нас случалось, что всякий раз, когда мы хотим узнать об истории какой-либо страны, памятниках, телесериалах и фильмы, жизнь знаменитостей и их карьера, инциденты из прошлого или текущие события, наш первый выбор — Википедия. Умные люди используют его, чтобы получить широкий спектр знаний и звучать еще умнее. Но задумывались ли вы когда-нибудь, насколько он огромен? Сколько у него документов/статей?
Умные люди используют его, чтобы получить широкий спектр знаний и звучать еще умнее. Но задумывались ли вы когда-нибудь, насколько он огромен? Сколько у него документов/статей?
В настоящее время в Википедии около 5,98 миллионов статей, и их количество увеличивается с каждым днем. Есть большое разнообразие статей из всех областей. Мы можем использовать эти данные для создания множества интересных приложений. Каким было бы ваше следующее интересное приложение, если бы у вас был доступ к этим данным? Как получить весь этот набор данных? Даже если вы его получите, какой объем вычислений потребуется для его обработки?
Ответы на все эти вопросы.
В этой статье я хочу создать набор данных о знаменитостях. Все популярные люди прошлого или настоящего, у которых есть страницы в Википедии, такие как Вират Кохли, Сачин Тендулкар, Рики Понтинг из Cricket, Брэд Питт, Леонардо ДиКаприо, Амитабх Баччан из фильмов, физики, такие как Альберт Эйнштейн, Исаак Ньютон и т.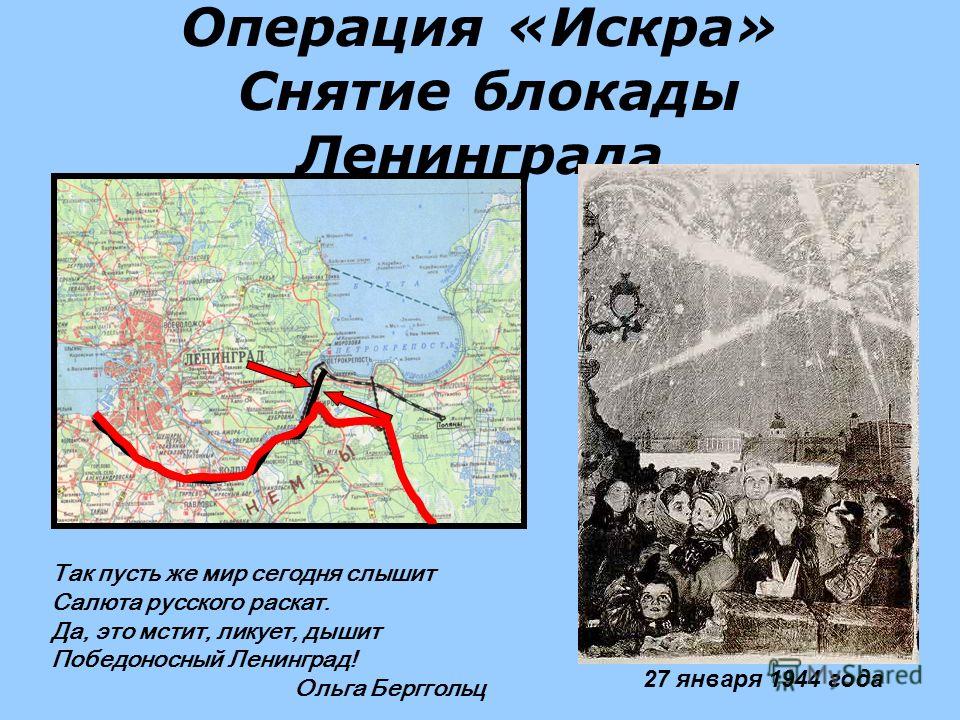 д. Я буду используйте Apache Spark (PySpark) для обработки этого массивного набора данных.
д. Я буду используйте Apache Spark (PySpark) для обработки этого массивного набора данных.
Для начала работы нам понадобится дамп Википедии. Дамп Википедии можно скачать в формате XML отсюда. Он постоянно обновляется и содержит последние данные из Википедии.
Скрипт для разбора XML-файла Википедии
Затем этот загруженный XML-код можно очень легко проанализировать с помощью бесплатного пакета Python. Подробнее о том, как использовать пакет, можно узнать здесь.
После завершения синтаксического анализа проанализированная структура Каталога будет выглядеть так.
Проанализированная структура каталога
Каждый каталог состоит из нескольких файлов с открытым текстом. Снимок содержимого файла
Снимок содержимого файла
Каждый файл содержит несколько статей Википедии. Каждая статья начинается с тега  Мы будем использовать инфраструктуру распределенных систем Apache Spark (PySpark) для выполнения задачи, которая займет от 10 до 15 минут с разумным количеством исполнителей.
Мы будем использовать инфраструктуру распределенных систем Apache Spark (PySpark) для выполнения задачи, которая займет от 10 до 15 минут с разумным количеством исполнителей.
Apache Spark
Apache Spark — это молниеносная технология кластерных вычислений, предназначенная для быстрых вычислений. Он основан на Hadoop MapReduce и расширяет модель MapReduce, чтобы эффективно использовать ее для большего количества типов вычислений, включая интерактивные запросы и потоковую обработку. Главной особенностью Spark является его вычислительный кластер в памяти , который увеличивает скорость обработки приложения.
Некоторые термины и функции преобразования Apache Spark (необязательно)
Этот раздел является необязательным. Этот раздел предназначен для новичков в Spark или для тех, кто хочет быстро освежить некоторые функции преобразования Spark, прежде чем продолжить. Чтобы узнать больше об этих функциях, перейдите по этой ссылке.
- RDD : RDD (Resilient Distributed Dataset) — это фундаментальная структура данных Apache Spark, которая представляет собой неизменный набор объектов, которые вычисляются на другом узле кластера. RDD — это распределенная коллекция элементов данных, разбросанных по многим машинам в кластере.
- DataFrame : DataFrame — это распределенная коллекция данных, организованных в именованные столбцы. Концептуально он аналогичен таблице в реляционной базе данных.
- map() : Функция карты перебирает каждую строку в RDD и разделяет ее на новую RDD. Используя преобразование map(), мы берем любую функцию, и эта функция применяется к каждому элементу RDD.
Использование функции преобразования map()
- flatMap() : С помощью функции flatMap() для каждого входного элемента у нас есть много элементов в выходном СДР. Самое простое использование flatMap() — разбить каждую входную строку на слова.

Использование функции преобразования flatMap()
- filter() : Функция Spark RDD filter() возвращает новый RDD, содержащий только элементы, соответствующие предикату.
Использование функции преобразования filter()
- целыетекстовые файлы(): целыетекстовые файлы возвращает PairRDD с ключом, являющимся путем к файлу, и значением, являющимся содержимым файла.
Начало работы с задачей
Прежде всего, мы получим все данные, переданные в HDFS, и прочитаем данные, используя целые текстовые файлы.
data = sc.wholeTextFiles("hdfs:///Data_w/*/*") Выходные данные будут иметь парные значения RDD, где ключ — это путь к файлу, а содержимое — значение. Мы можем избавиться от пути к файлу и просто работать с содержимым. Содержимое каждого файла содержит несколько статей Википедии, разделенных тегом 
страницы = data.flatMap(лямбда x :(x[1].split(''))) Когда у нас есть все статьи, нам нужно найти, о чем эта статья. Каждая статья состоит из первой строки, являющейся заголовком, а остальные — содержанием. Мы можем использовать эту информацию для преобразования каждой статьи в пару «ключ-значение», где ключ — это заголовок, а значение — содержание.
Моментальный снимок каждой статьиФункция извлечения заголовкаФункция извлечения содержимого
страницы = data.flatMap(lambda x :(x[1].split(''))).map(lambda x : (get_title(x ),get_content(x))) Далее следует отфильтровать только статьи, относящиеся к людям (знаменитостям). Прежде чем написать для него логику, давайте посмотрим, как выглядят некоторые страницы знаменитостей.
Вики-страница сэра Исаака НьютонаВики-страница Вирата КолиВики-страница Брэда ПиттаВики-страница Майкла Джексона
Давайте также взглянем на некоторые страницы не знаменитостей.
Вики-страница СШАВики-страница Тадж-Махала, Индия
Чем страница знаменитости отличается от страницы не-знаменитостей? Что общего на всех страницах знаменитостей?
Большинство страниц знаменитостей в первом предложении содержат дату рождения.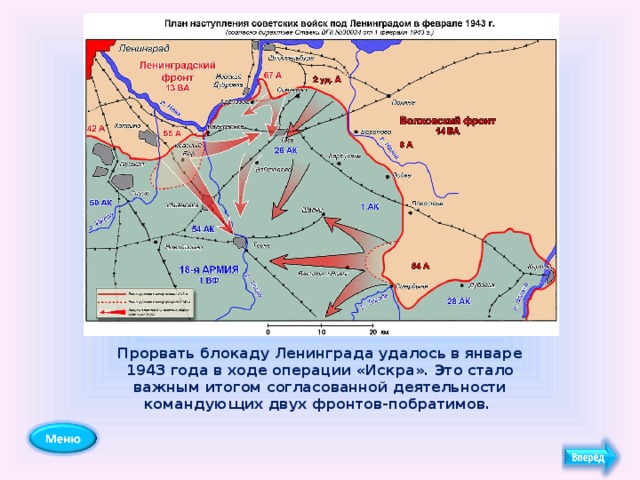 Дата рождения представлена в одном из следующих двух форматов в данных Википедии:
Дата рождения представлена в одном из следующих двух форматов в данных Википедии:
- Месяц Дата, Год: Нравится 12 августа 1993 г.
- Дата Месяц Год: Нравится 12 августа 1993 г.
Мы можем использовать этот факт для быстрой фильтрации из всех страниц знаменитостей. Я буду использовать Regex, чтобы найти этот формат.
Код для проверки того, является ли вики-страница страницей знаменитостей или нет
Наконец, мы можем сохранить вывод в виде таблицы. Полный код выглядит так:
Весь код проекта
Всего в Википедии около 5,98 миллионов статей. Наш набор данных о знаменитостях содержит 1,38 миллиона статей. Список всех знаменитостей и наборы данных, полученные вместе с кодом, можно найти здесь.
Набор данных содержит статьи о Майкле Джексоне, Амитабхе Баччане, Брэде Питте, Сачине Тендулкаре, М.С. Дони и всех других знаменитостях, о которых мы могли подумать и проверить.
Википедия — одно из лучших мест для поиска всей возможной информации в Интернете. Мы можем использовать его для создания многих интересных приложений, вашего следующего большого и интересного проекта НЛП. С использованием Apache Spark обработка этих массивных данных становится простой задачей. Всего за 20–25 строк кода мы можем создать из него большинство интересных наборов данных.
Мы можем использовать его для создания многих интересных приложений, вашего следующего большого и интересного проекта НЛП. С использованием Apache Spark обработка этих массивных данных становится простой задачей. Всего за 20–25 строк кода мы можем создать из него большинство интересных наборов данных.
Требуется много усилий, чтобы написать хороший пост с ясностью и понятностью для аудитории. Я буду продолжать пытаться воздать должное своей работе. Подписывайтесь на меня по адресу Medium и читайте мои предыдущие посты. Жду отзывов и конструктивной критики. Список всех знаменитостей и наборы данных, полученные вместе с кодом, можно найти здесь.
Мой канал Youtube для большего контента:
Абхишек Мунголи
Привет, ребята, добро пожаловать на канал. Канал нацелен на освещение различных тем из машинного обучения, науки о данных…
www.youtube.com
- https://www.tutorialspoint.com/apache_spark/apache_spark_introduction. htm
- https://spark.apache.org/
- https://en.wikipedia.org/ wiki/Apache_Spark
- https://en.wikipedia.org/wiki/MapReduce
- https://data-flair.training/blogs/spark-rdd-operations-transformations-actions/
- https://data- flair.training/blogs/spark-rdd-tutorial/
https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/ - https://www.analyticsvidhya.com/blog/2019/10/pyspark-for-beginners-first-steps-big-data-analysis/
- https://blog.softhints.com/python-regex- match-date/
 htm
htmАнализ текста Википедии с помощью pySpark
Spark повышает удобство использования, предлагая богатый набор API и упрощая разработчикам написание кода. Программы в Spark в 5 раз меньше, чем MapReduce. API Spark Python (PySpark) предоставляет модель программирования Spark для Python. Чтобы изучить основы Spark, прочитайте руководство по программированию на Scala; ему должно быть легко следовать, даже если вы не знаете Scala.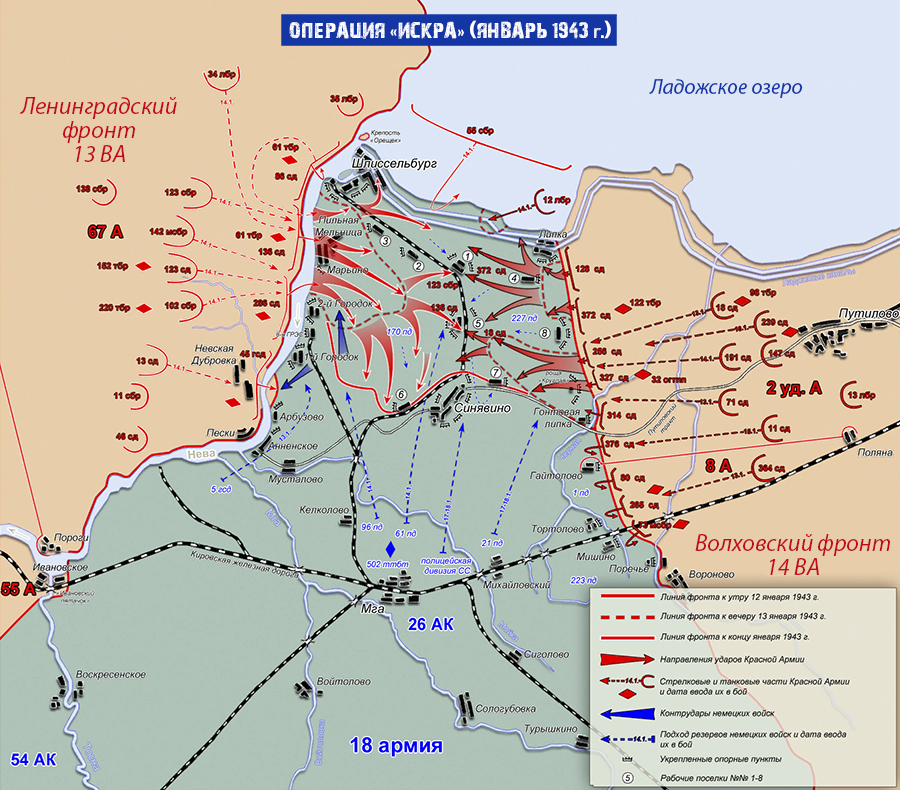 pySpark предоставляет простую в использовании программную абстракцию и параллельную среду выполнения, мы можем думать об этом как: «Вот операция, запустите ее для всех данных».
pySpark предоставляет простую в использовании программную абстракцию и параллельную среду выполнения, мы можем думать об этом как: «Вот операция, запустите ее для всех данных».
Для использования Spark разработчики пишут программу-драйвер, которая реализует высокоуровневый поток управления своего приложения и параллельно запускает различные операции на узлах кластера.
Типичный жизненный цикл программы Spark —
- Создание RDD из какого-либо внешнего источника данных или распараллеливание коллекции в программе-драйвере.
- Ленивое преобразование базовых СДР в новые СДР с использованием преобразований.
- Кэшируйте некоторые из этих RDD для повторного использования в будущем.
- Выполнение действий для выполнения параллельных вычислений и получения результатов.
Таким образом, у нас есть парадигма параллельной обработки ведущий-ведомый, то есть мы пишем команды на главной машине, она отправляет задачи рабочим, они вычисляют и отправляют результаты обратно, но также сохраняют в памяти любые RDD, которые они могли создать вместе способ выполнения задания.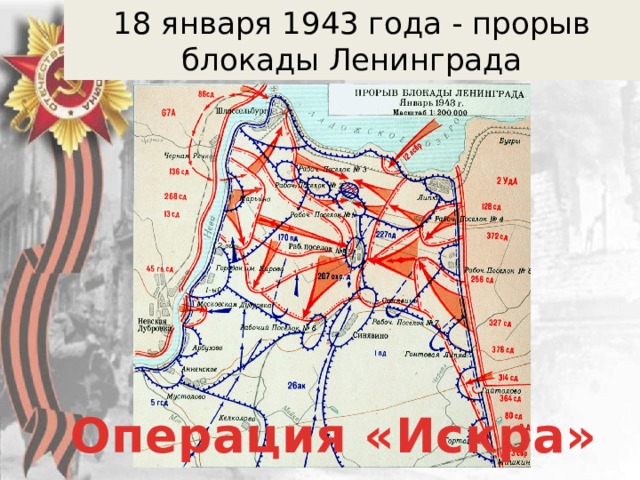 В следующий раз, когда мы выполним запрос, сработают постоянные RDD в памяти, и результаты будут вычисляться намного быстрее. Таким образом, объединяя преобразования и действия, мы можем писать программы так же, как и mapreduce. 90-9a-zA-Z ]», «, text)
В следующий раз, когда мы выполним запрос, сработают постоянные RDD в памяти, и результаты будут вычисляться намного быстрее. Таким образом, объединяя преобразования и действия, мы можем писать программы так же, как и mapreduce. 90-9a-zA-Z ]», «, text)
возврат текста def wordCount(wordListRDD):
return wordListRDD.map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b)
removePunctuation : Функция Python для удаления знаков препинания, перевода текста в нижний регистр и удаления начальных и конечных пробелов.
wordCount : Функция Python для создания пары RDD со словом и количеством его вхождений из RDD слов. Здесь мы сначала применяем функцию карты, чтобы создать пару RDD (слово, 1) для каждого вхождения слова в текст. Затем мы использовали преобразование reduceByKey() для СДР пар (K, V), которое возвращает СДР пар (K, V), где значения для каждого ключа агрегируются с использованием заданной функции сокращения 9. 0218 функц. Например: Если функция карты создает n пар для слова xyz как (xyz,1),…,(xyz,1), то reduceByKey() вернет пару с агрегированным значением для каждого ключа (здесь (xyz,n )).
0218 функц. Например: Если функция карты создает n пар для слова xyz как (xyz,1),…,(xyz,1), то reduceByKey() вернет пару с агрегированным значением для каждого ключа (здесь (xyz,n )).
Первое, что должна сделать программа Spark, — это создать объект SparkContext, который сообщает Spark, как получить доступ к кластеру. Чтобы создать SparkContext , сначала необходимо создать объект SparkConf, содержащий информацию о приложении.
conf = SparkConf().setAppName(appName).setMaster(мастер)
sc = SparkContext(conf=conf)
Затем мы создаем базовый RDD, читая текстовый файл (дамп википедии) с помощью объекта SparkContext. Spark определяет, что мы хотим создать RDD с 8 частями из этого текстового файла. Когда мы это делаем, происходит ленивая оценка, это означает, что прямо сейчас не происходит никакого выполнения. Все, что происходит, — это то, что Spark записывает, как создать RDD из этого текстового файла. Так что на самом деле ничего не происходит, пока мы не выполним действие. Мы пока строим только рецепт.
Мы пока строим только рецепт. Метод textFile() принимает необязательный второй аргумент для управления количеством разделов файла (здесь 8 ).
По умолчанию Spark создает один раздел для каждого блока файла (блоки по умолчанию имеют размер 64 МБ в HDFS), но вы также можете запросить большее количество разделов, передав большее значение. Обратите внимание, что у вас не может быть меньше разделов, чем блоков. Кроме того, файл может присутствовать в любой системе хранения, такой как Amazon S3, HDFS и т. д. Применение map(func) возвращает новый распределенный набор данных, сформированный путем передачи каждого элемента источника через функцию 9.0218 функция . Итак, здесь мы очищаем текст, применяя функцию removePunctuation для удаления пунктуации из каждой строки текста.
wikipediaRDD = (sc .textFile(«…fileName…», 8) .map(removePunctuation))
Теперь мы создаем слова RDD, разбивая строки RDD на основе пробела, а затем удаляя пустые элементы с помощью filter( ).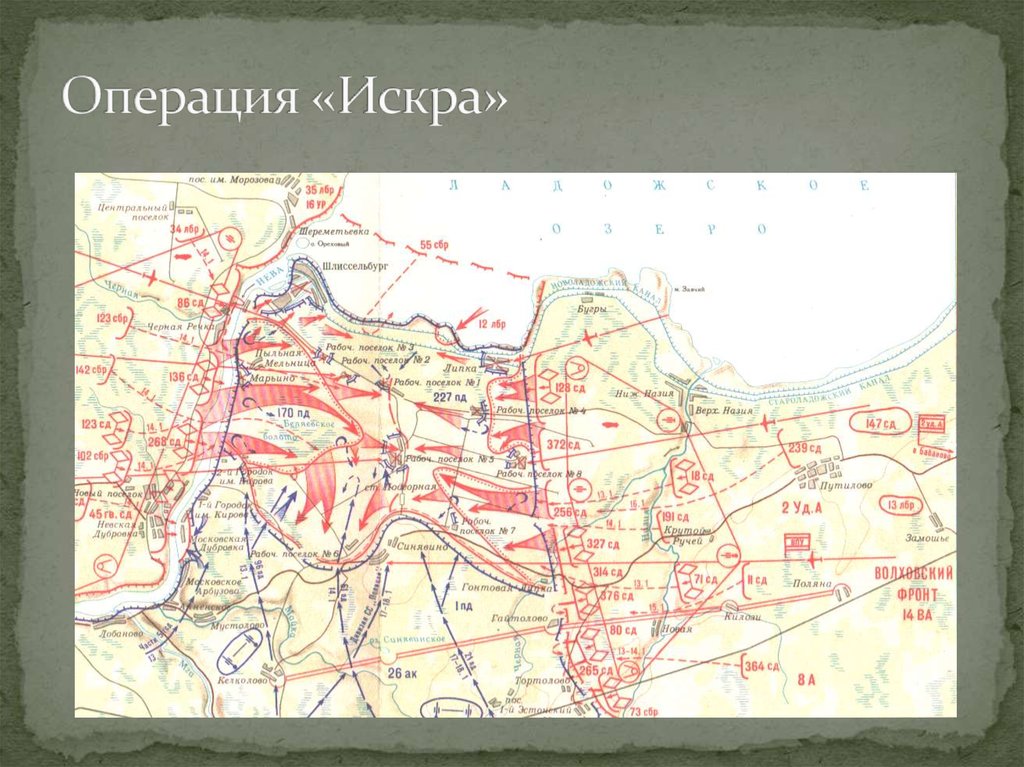
wikipediaWordsRDD = wikipediaRDD.flatMap(lambda x:x.split(‘ ‘))
wikiWordsRDD = wikipediaWordsRDD.filter(lambda x:x!=”)
Помните, что до сих пор мы применяли только преобразования, поэтому выполнение не выполнялось, и Spark сохранял только последовательность преобразований, которые необходимо применить для создания окончательного RDD. Теперь мы создаем пару RDD формы (word, count) для каждого уникального слова из слов RDD и применяем действие takeOrdered(), которое заставляет Spark применять все преобразования, которые он зафиксировал до сих пор, чтобы вернуть окончательные результаты. Действие takeOrdered() возвращает первые n элементы RDD в виде списка, используя либо их естественный порядок, либо пользовательский компаратор. Здесь он возвращает 15 лучших слов из парного RDD, используя собственный компаратор в качестве лямбда-функции Python.
top15WordsAndCounts = wordCount(wikiWordsRDD).takeOrdered(15,key=lambda (k,v):-v)
Таким образом, мы можем легко использовать Spark для исследования данных и задавать различные вопросы для анализа огромного неструктурированный набор данных (здесь текст Википедии).